Julian Andres Klode: APT 2.0 released
After brewing in experimental for a while, and getting a first outing in
the Ubuntu 19.10 release; both as 1.9, APT 2.0 is now landing in unstable.
1.10 would be a boring, weird number, eh?
Compared to the 1.8 series, the APT 2.0 series features several new features,
as well as improvements in performance, hardening. A lot of code has been
removed as well, reducing the size of the library.
Highlighted Changes Since 1.8
Highlighted Changes Since 1.8
New Features
-
Commands accepting package names now accept aptitude-style patterns. The
syntax of patterns is mostly a subset of aptitude, see
apt-patterns(7) for
more details.
-
apt(8) now waits for the dpkg locks - indefinitely, when connected
to a tty, or for 120s otherwise.
-
When apt cannot acquire the lock, it prints the name and pid of the process
that currently holds the lock.
-
A new
satisfy command has been added to apt(8) and apt-get(8)
-
Pins can now be specified by source package, by prepending
src: to the
name of the package, e.g.:
Package: src:apt
Pin: version 2.0.0
Pin-Priority: 990
Will pin all binaries of the native architecture produced by the source
package apt to version 2.0.0. To pin packages across all architectures,
append :any.
Performance
-
APT now uses libgcrypt for hashing instead of embedded reference
implementations of MD5, SHA1, and SHA2 hash families.
-
Distribution of rred and decompression work during update has been
improved to take into account the backlog instead of randomly
assigning a worker, which should yield higher parallelization.
Incompatibilities
- The apt(8) command no longer accepts regular expressions or wildcards as
package arguments, use patterns (see New Features).
Hardening
- Credentials specified in auth.conf now only apply to HTTPS sources,
preventing malicious actors from reading credentials after they redirected
users from a HTTP source to an http url matching the credentials in
auth.conf. Another protocol can be specified, see apt_auth.conf(5) for
the syntax.
Developer changes
-
A more extensible cache format, allowing us to add new fields without
breaking the ABI
-
All code marked as deprecated in 1.8 has been removed
-
Implementations of CRC16, MD5, SHA1, SHA2 have been removed
-
The apt-inst library has been merged into the apt-pkg library.
-
apt-pkg can now be found by pkg-config
-
The apt-pkg library now compiles with hidden visibility by default.
-
Pointers inside the cache are now statically typed. They cannot be
compared against integers (except 0 via nullptr) anymore.
python-apt 2.0
python-apt 2.0 is not yet ready, I m hoping to add a new cleaner
API for cache access before making the jump from 1.9 to 2.0 versioning.
libept 1.2
I ve moved the maintenance of libept to the APT team. We need to investigate
how to EOL this properly and provide facilities inside APT itself to
replace it. There are no plans to provide new features, only bugfixes
/ rebuilds for new apt versions.
-
Commands accepting package names now accept aptitude-style patterns. The
syntax of patterns is mostly a subset of aptitude, see
apt-patterns(7)for more details. -
apt(8)now waits for the dpkg locks - indefinitely, when connected to a tty, or for 120s otherwise. - When apt cannot acquire the lock, it prints the name and pid of the process that currently holds the lock.
-
A new
satisfycommand has been added toapt(8)andapt-get(8) -
Pins can now be specified by source package, by prepending
src:to the name of the package, e.g.:
Will pin all binaries of the native architecture produced by the source packagePackage: src:apt Pin: version 2.0.0 Pin-Priority: 990aptto version 2.0.0. To pin packages across all architectures, append:any.
Performance
-
APT now uses libgcrypt for hashing instead of embedded reference
implementations of MD5, SHA1, and SHA2 hash families.
-
Distribution of rred and decompression work during update has been
improved to take into account the backlog instead of randomly
assigning a worker, which should yield higher parallelization.
Incompatibilities
- The apt(8) command no longer accepts regular expressions or wildcards as
package arguments, use patterns (see New Features).
Hardening
- Credentials specified in auth.conf now only apply to HTTPS sources,
preventing malicious actors from reading credentials after they redirected
users from a HTTP source to an http url matching the credentials in
auth.conf. Another protocol can be specified, see apt_auth.conf(5) for
the syntax.
Developer changes
-
A more extensible cache format, allowing us to add new fields without
breaking the ABI
-
All code marked as deprecated in 1.8 has been removed
-
Implementations of CRC16, MD5, SHA1, SHA2 have been removed
-
The apt-inst library has been merged into the apt-pkg library.
-
apt-pkg can now be found by pkg-config
-
The apt-pkg library now compiles with hidden visibility by default.
-
Pointers inside the cache are now statically typed. They cannot be
compared against integers (except 0 via nullptr) anymore.
python-apt 2.0
python-apt 2.0 is not yet ready, I m hoping to add a new cleaner
API for cache access before making the jump from 1.9 to 2.0 versioning.
libept 1.2
I ve moved the maintenance of libept to the APT team. We need to investigate
how to EOL this properly and provide facilities inside APT itself to
replace it. There are no plans to provide new features, only bugfixes
/ rebuilds for new apt versions.
- The apt(8) command no longer accepts regular expressions or wildcards as package arguments, use patterns (see New Features).
Hardening
- Credentials specified in auth.conf now only apply to HTTPS sources,
preventing malicious actors from reading credentials after they redirected
users from a HTTP source to an http url matching the credentials in
auth.conf. Another protocol can be specified, see apt_auth.conf(5) for
the syntax.
Developer changes
-
A more extensible cache format, allowing us to add new fields without
breaking the ABI
-
All code marked as deprecated in 1.8 has been removed
-
Implementations of CRC16, MD5, SHA1, SHA2 have been removed
-
The apt-inst library has been merged into the apt-pkg library.
-
apt-pkg can now be found by pkg-config
-
The apt-pkg library now compiles with hidden visibility by default.
-
Pointers inside the cache are now statically typed. They cannot be
compared against integers (except 0 via nullptr) anymore.
python-apt 2.0
python-apt 2.0 is not yet ready, I m hoping to add a new cleaner
API for cache access before making the jump from 1.9 to 2.0 versioning.
libept 1.2
I ve moved the maintenance of libept to the APT team. We need to investigate
how to EOL this properly and provide facilities inside APT itself to
replace it. There are no plans to provide new features, only bugfixes
/ rebuilds for new apt versions.
- A more extensible cache format, allowing us to add new fields without breaking the ABI
- All code marked as deprecated in 1.8 has been removed
- Implementations of CRC16, MD5, SHA1, SHA2 have been removed
- The apt-inst library has been merged into the apt-pkg library.
- apt-pkg can now be found by pkg-config
- The apt-pkg library now compiles with hidden visibility by default.
- Pointers inside the cache are now statically typed. They cannot be compared against integers (except 0 via nullptr) anymore.


 Here is my monthly update covering what I have been doing in the free software world in September 2017 (
Here is my monthly update covering what I have been doing in the free software world in September 2017 (

 I am starting a work with the students of
I am starting a work with the students of 

 Since the past few weeks I have been researching and working on creating a white label version of Lumicall with my mentors Daniel, Juliana and Bruno.
Lumicall is a free and convenient app for making encrypted phone calls from Android. It uses the SIP protocol to interoperate with other apps and corporate telephone systems. Think of any app that you use to call others using an SIP ID.
Since the past few weeks I have been researching and working on creating a white label version of Lumicall with my mentors Daniel, Juliana and Bruno.
Lumicall is a free and convenient app for making encrypted phone calls from Android. It uses the SIP protocol to interoperate with other apps and corporate telephone systems. Think of any app that you use to call others using an SIP ID.
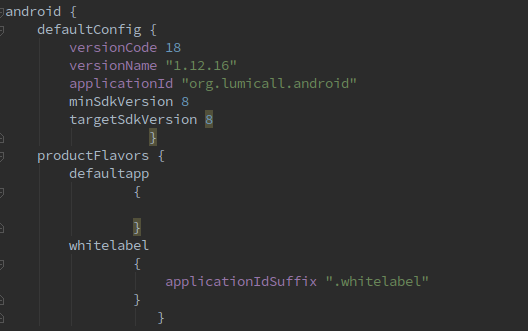 Note: You have to define at least two flavors to be able to build multiple variants.
Note: You have to define at least two flavors to be able to build multiple variants.

 The image has been taken from
The image has been taken from  The image comes from
The image comes from 


 Or this
Or this









